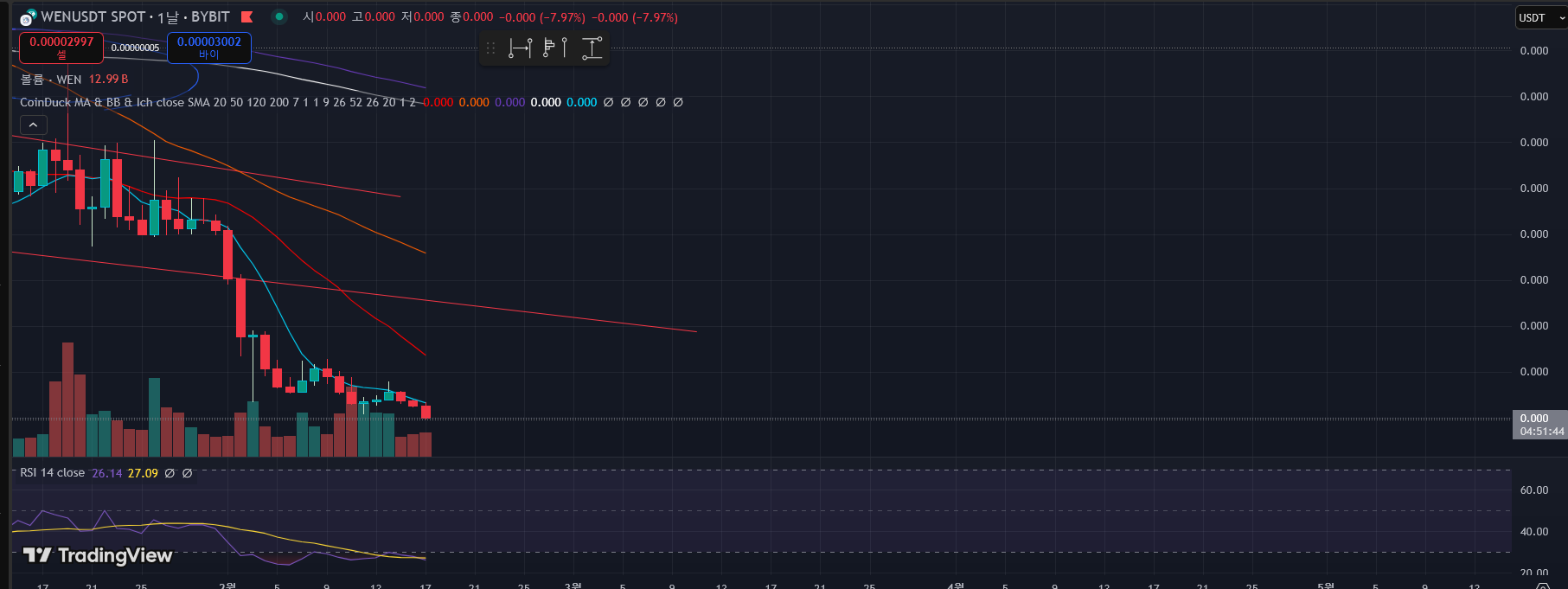
https://moluuu.tistory.com/116 아르헨티나 십좆통령이 솔라나 생태계에서 아주 깽판을쳐서 + 알트들의 곡소리로 wen은 결국 거진 -60% 이상을 달리고 있다 어디까지 떨어질지 감도 잡히지 않는다.. 이평선은 사실 딱히 볼게 없다 월봉까지 모두 이평선 아래에 있기 때문에 지지는 없고 저항만 오지게 많은 상황그나마 볼만한 것은 rsi가 주봉상 과매도권에 들어섰고 일봉으론 하락다이버전스가 보인다는 것? 그리고 크라켄 거래소에서 왠지는 모르겠는데 더이상 선물관련 정보를 제공하지 않는다 상폐한거 같진 않던데 전에도 한번 이런적 있었는데 떼잉 아무튼 크라켄에서 가격은 하락을 하는데 cvd는 상승을 하는 기현상을 보여주고 있음 또한 바이비트 cvd도 갑자기 증가를 하는데 참고로 폴로닉스는..