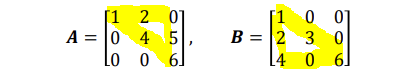행렬(Matrix)- 일반적으로 2차원인 경우 행렬이라고 함- 3차원 이상은 텐서 행렬의 정의- m * n (row * column) 직사각형 모양으로 배열한 것- 여기서 m * n이 행렬의 크기임여기서 i열 j행의 원소를 a(아래첨자)ij 라고 하며 성분이라고도 함 행렬의 종류1. 정방행렬 (Square Matrix)행과 열의 수가 같은 것주대각성분: 행열이 같은 숫자를 가지는 a()mn들의 집합? 2. 영행렬(Zero Matrix)모든 성분이 0인 행렬 3. 단위행렬(Identity Matrix)주대각성분이 1이고 나머지는 0인 것I 또는 E로 표기함 4. 삼각행렬(Triangular Matrix)정방행렬 중 주 대각선 아래 또는 위가 모두 0인 것상삼각행렬: 정방행렬 중 주 대각선 아래가 모두 0인..